
InspireFace Architecture
InspireFace SDK adopts a layered modular architecture design that provides high-performance face recognition capabilities across diverse hardware platforms. The system is structured into five main layers: Client Interface, Session Management, Core Services, Engine Layer, and Platform Support.
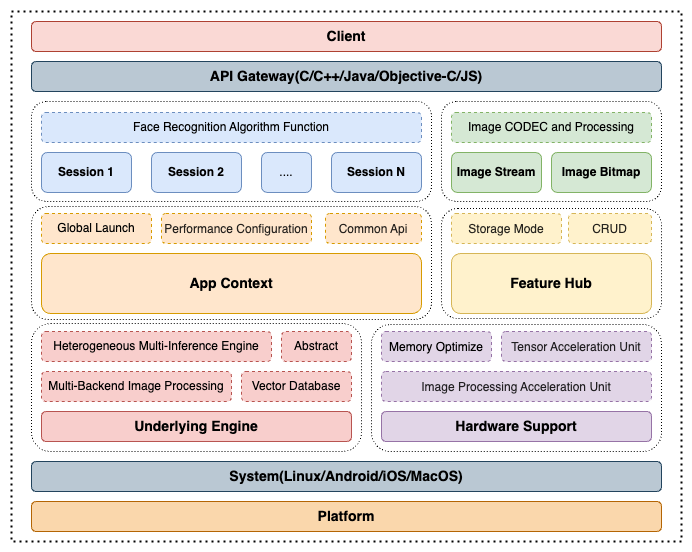
At the top level, the Client Interface Layer provides a unified C API that abstracts complex implementations, allowing developers to easily integrate face detection, recognition, and liveness detection functionalities. The Session Management Layer serves as the core processing unit, supporting multiple concurrent Session instances with independent configurations and resource isolation, alongside comprehensive image codec and processing capabilities for various formats (RGB, BGR, YUV).
The Core Services Layer encompasses two global services: App Context for SDK lifecycle and resource management, and Feature Hub for centralized face feature vector storage, search, and comparison with support for both memory and persistent storage modes.
The Engine Layer represents the performance cornerstone, featuring a multi-backend heterogeneous neural network inference architecture that intelligently selects optimal backends including ONNX Runtime, TensorRT, CoreML, and MNN based on available hardware resources.
The Hardware Support Layer provides comprehensive acceleration across multiple platforms. GPU acceleration includes full CUDA support for NVIDIA hardware with Tensor Core optimization, OpenCL compatibility for AMD devices, and native Metal framework support for Apple platforms. Embedded NPU support encompasses ARM Mali NPU, Rockchip NPU, and Apple NPU Engine(ANE) architectures. CPU optimization leverages ARM NEON SIMD instructions, Intel AVX/SSE extensions, and OpenMP-based multi-threading. Additionally, 2D image processing acceleration utilizes hardware engines like ARM Mali GPU, Rockchip RGA for efficient format conversion, scaling, and geometric transformations with DMA-optimized zero-copy memory management.
This architecture ensures optimal performance through intelligent hardware detection and resource scheduling while maintaining cross-platform compatibility and easy integration across Linux, Windows, Android, and iOS environments.